


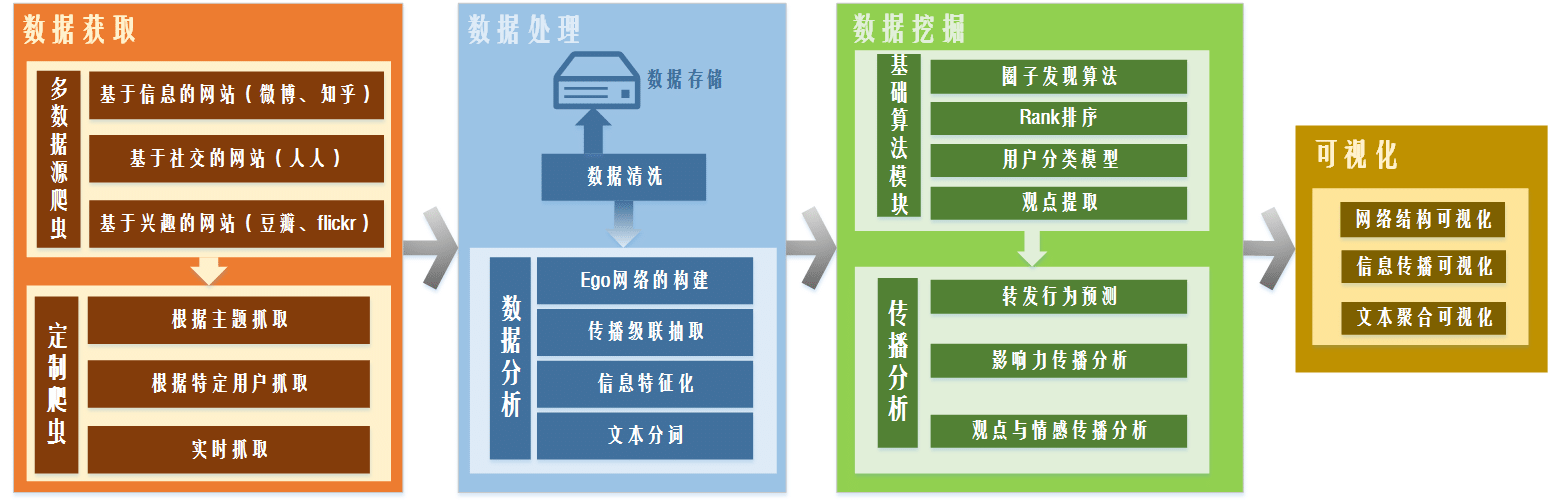
一、数据获取
本模块的作用是对相应的数据源进行获取工作,其中分为两个部分:
1. 多数据源爬虫
针对存在各种格式不一的线上社交网站,从社交的角度将对应的爬虫的分为三个部分:基于信息的网站,主要代表是微博、Twitter;基于熟人社交的网站,主要代表是人人、Facebook;基于兴趣的网站,主要代表是豆瓣和Flickr等共享网站。这里对网站的划分也就意味着我们数据获取的目的也存在划分。
2. 定制爬虫
针对平台的特定需求,我们提出定制爬虫的数据获取方式。具体分为:根据主题抓取,依据某一个事件主题对相应的数据进行抓取;特定用户抓取,对指定用户的相关信息进行抓取;实时抓取,根据前端需要的信息进行实时的更新抓取。
二、数据处理
本模块的主要作用是对抓取得到的数据进行清洗、分析、存储三个步骤,是在数据挖掘之前必要的预处理步骤。
1. 数据清洗
主要目的是为了对前一个模块中获取到的不规整源数据进行过滤,对不完整的信息进行清除以及给出相应不完整信息的情况。
2. 数据存储
对清洗后相应的数据进行离线存储备份。
3. 数据分析
该子模块是数据处理模块的核心,是为数据挖掘准备好数据格式的必要步骤。
3.1. Ego网络的重构
ego network,它的节点是由唯一的一个中心节点(ego),以及这个节点的邻居(alters)组成的,它的边只包括了ego和alter之间,以及alter与alter之间的边。本功能是对离线数据以及在线数据中的网络结构进行重复原。
3.2. 传播级联的提取
传播级联是指信息在用户中一跳接一跳的传播构成的级联关系。通过在对清洗后的数据中找到相应的传播关系,进一步对级联建立起合适的数据结构进行提取。
3.3. 信息特征化
将所有的对应信息分为个人信息、结构信息、微博信息三大块,将其中的全部信息特征向量化,为下一步挖掘打下基础。
3.4. 文本分词
针对源数据中微博内容进行分词操作,通过将完整的单条微博进行停用词去除等文本操作,将整条划分为单个词向量。
三、数据挖掘
本模块是基于数据处理的基础上,进行相应的数据挖掘算法。主要分为两大块:
1. 基础算法模块
该模块的主要实现主要的基础功能算法模块包括:
1.1. 圈子发现算法
对ego网络中的网络结构进行圈子划分整理,运行对应的圈子划分算法。
1.2. Rank排序
针对数据中网络关注的结构关系,对节点重要性进行排序,其中主要的基本算法是PageRank算法。
1.3. 观点提取
对实时与离线数据中的微博所表达的观点进行提取,主要利用文本挖掘算法,围绕热点事件的微博进行观点与情感的提取。
2. 传播算法模块
本模块目的在展示我们的算法成果,特别是在传播算法方面。主要包括微博转发的行为预测、影响力传播的模型、观点与情感传播分析等。
四、可视化
本模块用来展示整个平台的成果,是与用户交互的主要界面。根据平台整体的规划,可分为以下几个方面:
1. 网络结构可视化
对数据挖掘中得到的网络结构与圈子进行可视化,结合传播过程对单条微博在圈子中的转发情况进行可视化;
2. 信息传播可视化
对单条微博、某个事件的相关微博在整体网络中的传播进行可视化。同时,对传播的路径中每个用户给出对应的影响力值、情感状态、rank位置等与传播算法相关的结果。
3. 文本聚合可视化
对单个用户、某个事件的相关文本信息进行可视化,主要包括词频统计信息、情感文本变化信息和兴趣变化信息。
整个平台运行在linux(Ubuntu 14.04)集群之上。爬虫抓取系统交由Docker云平台进行托管,每次需要使用相应的爬虫对数据进行获取时,都会通过Docker启动一个包含指定爬虫的容器,容器的生命周期为从爬虫启动到抓取数据结束。对于抓取到的数据使用txt格式进行保存,并上传到HDFS分布式文件系统中。所有的微博数据都通过HDFS保存和管理,对于较小的测试集可以格式化后保存在MongoDB当中方便使用。针对数据集的主要操作都是通过Spark来完成的,需要对数据进行查询时使用Spark SQL完成,需要对网络进行图计算时使用Spark Graphx完成,需要使用机器学习算法时使用Spark MLib完成,针对一些Spark MLib中尚未实现的算法可以通过相对成熟的Mahout来完成。最后,使用Javasc[ant]ript实现的D3和Java实现的processing对分析,挖掘的结果进行可视化。
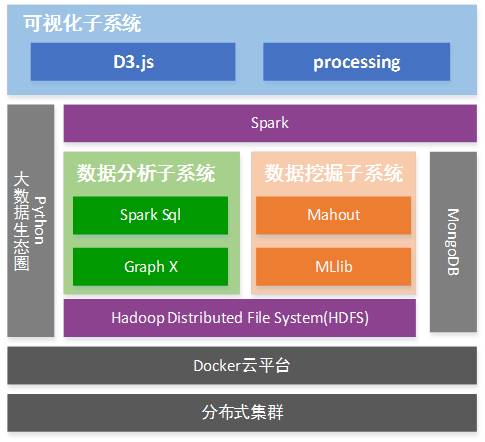
1. 基础设施:整个平台以主从方式(1 Master+8 Slaves)运行在linux(Ubuntu 14.04)集群之上,其中Master配置为4 cores(Intel Xeon 2.67GHz),8GB内存;Slave配置为2 cores(Intel Xeon 2.67GHz),6GB内存。
2. Docker云平台:Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。在这里,我们使用Docker对不同的爬虫进行托管,当系统需要对相关数据进行获取时,就会通过Docker启动一个包含对应爬虫的容器,容器伴随整个爬虫的生命周期,抓取结束后相关资源由Docker回收。由于数据源可能对数据获取进行限制,因此我们会在Docker中针对数据源的限制制定相应的规则以保证爬虫的启动保持对资源的负载均衡。
3. 数据存储:对于爬虫获取到的数据,我们根据不同的任务保存在不同命名规范下的txt文件当中,这里使用HDFS(Hadoop分布式文件系统)作为主要的数据存储仓库。通过调整HDFS的相关参数(如块大小,副本数)可以使HDFS在性能和容错上达到最优。对于某些实验可能需要较小的数据集,我们可以从HDFS中抽取部分数据格式化后存入MongoDB当中,这样更方便测试和使用。
4. 数据分析和挖掘:对于数据的分析和挖掘,我们主要使用Spark来完成,因为Spark能够提供比Hadoop MapReduce更加快速的数据处理能力和更加兼容的工具。针对一些统计性较强的数据分析工作,可以使用Spark SQL模块来完成;涉及到网络结构的计算,可以使用Spark Graphx;当需要应用机器学习算法时,可以使用Spark MLib来完成。对于正在发展的MLib,一些机器学习算法可能不够完善,对于这种情况,我们可以选择使用Apache Mahout在Hadoop平台上来完成相应的算法。
5. 数据可视化:对于数据分析和挖掘的结果,我们通过B/S的形式在网页中使用D3和processing进行展示。为了尽可能的表现出结果的特点和细节,我们对于不同结构和类型的结果使用不同的表,图和布局来实现。