


- 基于物理特性的图像去雾霾处理
- 基于行为的恶意程序行为分析与检测
- 图像融合中间件
室外场景图像常常因霾或者其他气溶胶粒子的存在而引起降质。当天气不佳时,对于距离成像设备较远的场景点而言,入射光常常会被大气中的气溶胶微粒所衰减。同时,由于大气中粒子的散射而产生的环境光照,也会随着光程的增加而提升亮度。因此,在这些降质图像中远离成像设备的目标,色彩和对比度都会变得很差。近年来学者们主要通过基于图像增强和基于物理模型两种方法对图像进行去雾霾处理。相较于基于图像增强的方法,基于物理模型的方法反演了图像的退化过程,更有效的避免了图像的失真,因此获得了更加广泛的应用。
基于物理模型的方法主要根据McCartney提出的大气散射模型进行处理,该模型表述为:I(x)=J(x)t(x)+(1-t(x))A,其中,x指的是图像中每个像素的位置;I(x)为最终进入成像设备的光线强度,亦即图像中该点的亮度;J(x)是指该点的场景照度,即在良好的天气环境下该点进入成像设备的光强;A是大气散射带来的光照;t(x)是传输率,反映了场景照度未经散射而到达成像设备的比例。在该模型中,传输率t(x)和大气光A是两个重要的参数,前者决定了去雾霾的程度,后者决定了复原图像的整体亮度。
针对以往方法中由于未正确估测大气光和忽视黄霾物理特性的缺陷,在认真分析上述模型中各个物理量的含义基础上,我们设计了一种图像去雾霾的新算法。该算法通过自适应的天空区域探测方法获取大气光,并通过新提出的图像自适应的通道均衡化方法进行色彩平衡以消除黄霾的颜色影响,并通过在改进参数的HSI空间处理来避免复原图像出现过饱和。如图所示,相较于传统方法,我们的算法在保持图像整体亮度,恢复局部细节,避免晕轮效应(一种在景深突变处产生的异常边缘)及消除黄霾带来的色偏上都具有更好的效果。




恶意程序大数据问题是现代恶意程序技术发展到一定程度后,传统方法难以处理的海量恶意程序问题。工业界著名的赛门铁克(Symantec)公司曾经统计了2002年之后每年收集到的互不相同的恶意程序数量,这一数量在2009年前为数百万,尚在传统方法可以处理的范围内,然而这之后的恶意程序数量极速爆炸,仅在2011年就收集到了超过四亿个独立的恶意程序样本。而这一数字仍在加速增长中,随着智能手机等移动互联网终端的普及,恶意程序的传播途径进一步多样化,对传统的恶意程序分析、分类等任务造成了极大的挑战。
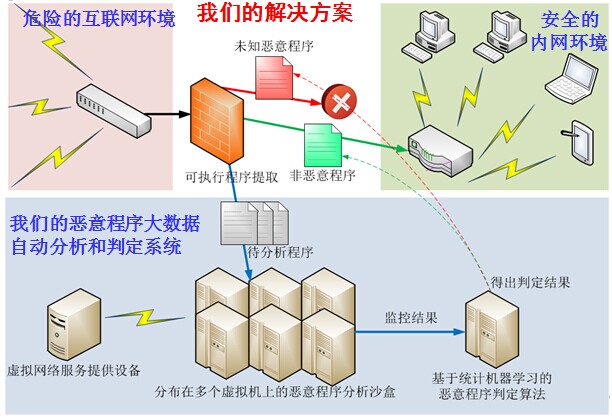
为应对恶意程序大数据问题,我们设计并实现了一套大数据环境下的恶意程序自动分析和判定系统。这套系统可以被部署在完全内网的外网入口处,首先对网络流量中的下载、邮件附件等内容中附带的可执行程序进行提取,之后这些待分析程序被送入部署在多个虚拟机上的恶意程序自动分析沙盒中,沙盒承载的拟真系统环境、常见主机事件、常见用户操作以及完整的虚拟网络服务能够最大限度地激发恶意程序的核心行为并在虚拟机监控层予以完整监控。沙盒得到的动态分析结果一方面通过行为抽象算法得到容易被用户理解的行为分析报告,另一方面通过特征提取算法得到用于判定其恶意性的高维稀疏特征。预先训练的统计机器学习算法能够充分学习大量训练数据中蕴含的统计规律,从而能够准确判定未知程序的恶意性。此外,我们的系统还可以用于云杀毒软件的服务器端、辅助手工恶意程序行为分析等多种应用场景。
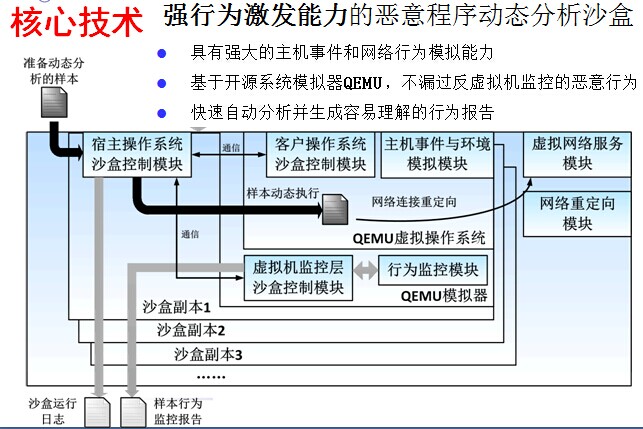
大数据环境下的恶意程序自动分析和判定系统的核心技术之一是具备强行为激发能力的恶意程序动态分析沙盒。传统的恶意程序行为分析沙盒普遍存在以下几个问题(1)对需要特定条件、特定用户操作和互联网环境的恶意程序行为激发能力弱;(2)抗虚拟机的恶意程序技术可以回避分析;(3)动态分析需要较长时间,效率较低。针对这几个问题,我们首先深入研究了恶意行为激发可能用到的主机事件、用户操作和互联网服务,并在我们的沙盒中充分提供了这些条件,从而最大程度上激发隐藏行为,提高行为分析的完整性。其次,我们的沙盒基于开源模拟器QEMU实现,不同于虚拟机的实现方式使沙盒对一般的反虚拟机手段完全免疫,任何沙盒内的操作都会得到监控。最后,我们将尽量精简的沙盒部署在服务器的多个虚拟机实例中运行,高度的可并行化确保了面对海量恶意程序样本时足够的分析效率。
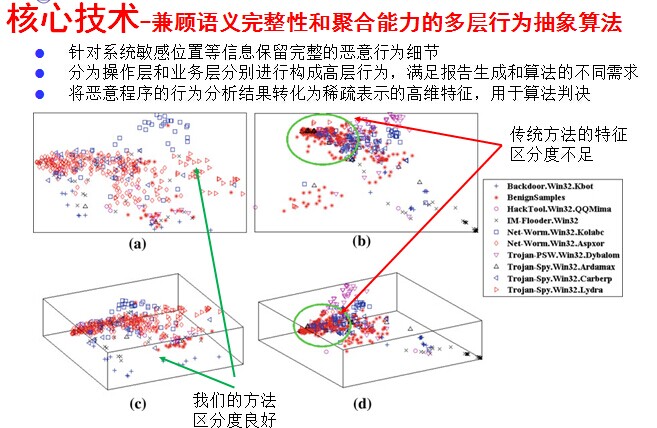
恶意程序分析沙盒得到的原始行为监控结果无论对于用户理解还是算法判决,都需要进一步处理。一方面,对于用户理解而言,原始行为监控结果的语义聚合程度过低是其主要的问题,恶意程序的核心业务逻辑分散在数千甚至数万个小的独立行为中,这需要一种智能的冗余去除和语义聚合机制。另一方面,对于算法判决而言,无格式的字符串构成的行为监控结果无法作为输入,需要通过某种转换方式将行为监控数据嵌入到向量空间中。我们设计了一种兼顾语义完整性和聚合能力的多层行为抽象算法,同时完成了行为抽象和特征提取任务,生成的行为报告可读性基本与手工分析无异,而嵌入到向量空间的特征比传统的n-gram等特征具有更好的区分能力。
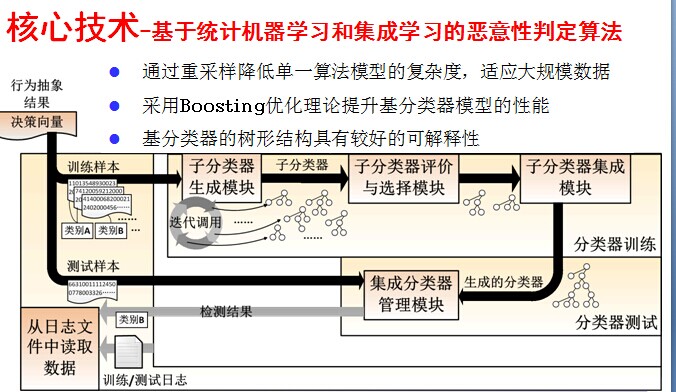
作为恶意性判定的核心,我们采用了基于统计机器学习和集成学习的恶意性判定算法。基于Boosting优化理论的集成学习框架能够有效提升基分类器的性能,而基于子空间重采样的基分类器设计能够降低单一算法模型的复杂度,这是大数据环境下机器学习面临的最大难题。此外,基分类器采用的树形结构具有很好的可解释性,在用户需要得知算法判定依据时,能够快速通过判定路径上的核心维度给出相应反馈。在此基础上,我们进一步引入了代价敏感机制和单类机器学习等,以控制判定算法的误检风险。对比实验表明,我们提出的算法较常用的机器学习算法具有更强的抑制误检率效果,同时保持了理想的检测率。