


研究团队承担的科研项目:
- 多模态心理大模型研究与应用 2023 ~ 2028
- 广东省“新一代人工智能”重点领域研发计划项目 (专题2) 2021 ~ 2023
- 手机AI自动曝光系统(小米手机) 2021 ~ 2022
- 大脑破译与人工智能基础理论研究(西安市科技创新项目,100万) 2019 ~ 2021
- 西电科研启动金 2018 ~ 2021
- JSPS Grants-in-Aid for Science Research C, PI 2015 ~ 2017
- JSPS Grant-in-Aid for Young Scientists B, PI 2013 ~ 2015
- International Exchanges Scheme (Royal Society, UK), Joint, PI: Prof. Peter McOwan, Queen Mary University of London, 2012 ~ 2013
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
团队研究方向:
- 多模态情感计算
情感是个体对外界价值关系产生的主观反应,也是智能的重要组成部分。在日常生活中,情感的反应是多模态的,人们会根据面部表情,语气、文字、肢体动作、生理指标(心率、血压、呼吸)等其他一些细微的变化来感知他人的情感状态。由于各模态所承载的情感信息并不相同,因此多模态结合能够有效进行信息互补,降低情感数据的模糊性,从而更好地完成识别分类任务。
情感计算在服务型机器人、审讯、娱乐等方面有了越来越多的应用,这也意味着针对模糊情感数据的处理具有广泛的应用前景。
以下是团队已取得的成果:
1. "Dataset-Aware Utopia Modality Contribution for Imbalanced Multimodal Learning". Information Fusion, 2025 (IF 14.7).
多模态学习时常常会出现模型对某一两个模态学习充分,但对其他模态学习不充分的现象,我们称之为多模态不平衡问题。现有的多模态平衡策略主要是尽量减少模态之间的贡献差异,然而却忽略了一个事实,即不同模态通常在本质上对预测任务的贡献并不相等,若一味约束主导模态,可能致使模型对主导模态欠拟合,导致模型无法充分利用多模态信息,从而收敛于局部最优点。此外,这些方法还忽略了一个事实,即不同模态的贡献应该是数据集相关的。 例如,在CMU-MOSEI数据集中,视觉比音频包含更丰富的情感信息。相比之下,在AVE数据集中,音频特征比视觉特征更能揭示任务相关信息,这说明了dataset-aware的模态贡献估计方法的必要性。
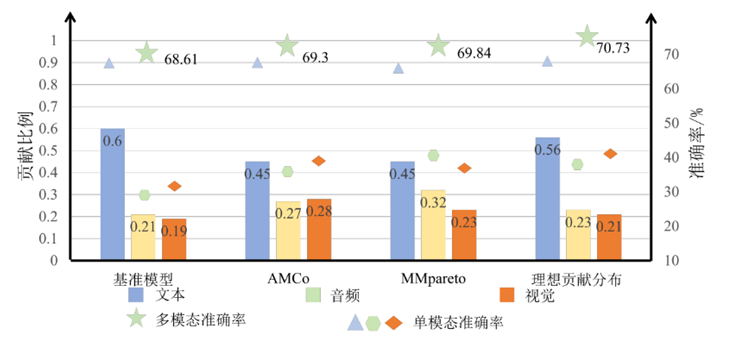

我们首次引入了模态的理想贡献分布(Utopia Contribution Distribution,UCD)的概念,指当模型达到全局最优时,每个模态对模型预测的贡献分布。为了获得这种UCD,我们提出了一种新颖的思路来估计每个模态的理想贡献比例,具体而言,使用群体风险来评估包括或排除该模态对模型预测的影响,进而估计模态的贡献比例。得到的UCD作为现有平衡策略的优化目标,使模型充分利用所有模态信息,大量的实验结果证实了该思路的有效性。不同于其他研究强调各模态贡献的均衡,我们新颖之处在于,训练期间不断估计每个模态对模型当前预测的实际贡献分布(Factual Contribution Distribution, FCD),将多模态学习优化转换成一个将FCD 与UCD 对齐的过程。
2. "Triple Disentangled Representation Learning for Multimodal Affective analysis", Information Fusion, 2024 (IF 14.7).
为了解决模态的异质性和信息的多样性导致的不精确或冗余的多模态表征,许多新兴的多模态研究侧重于将模态不变(r*)和模态特有的表征(u)从输入数据中进行解耦,然后将它们融合起来进行预测。然而,研究表明,模态特有的表征可能包含与任务无关或冲突的信息,这降低了学习到的多模态表征的有效性。
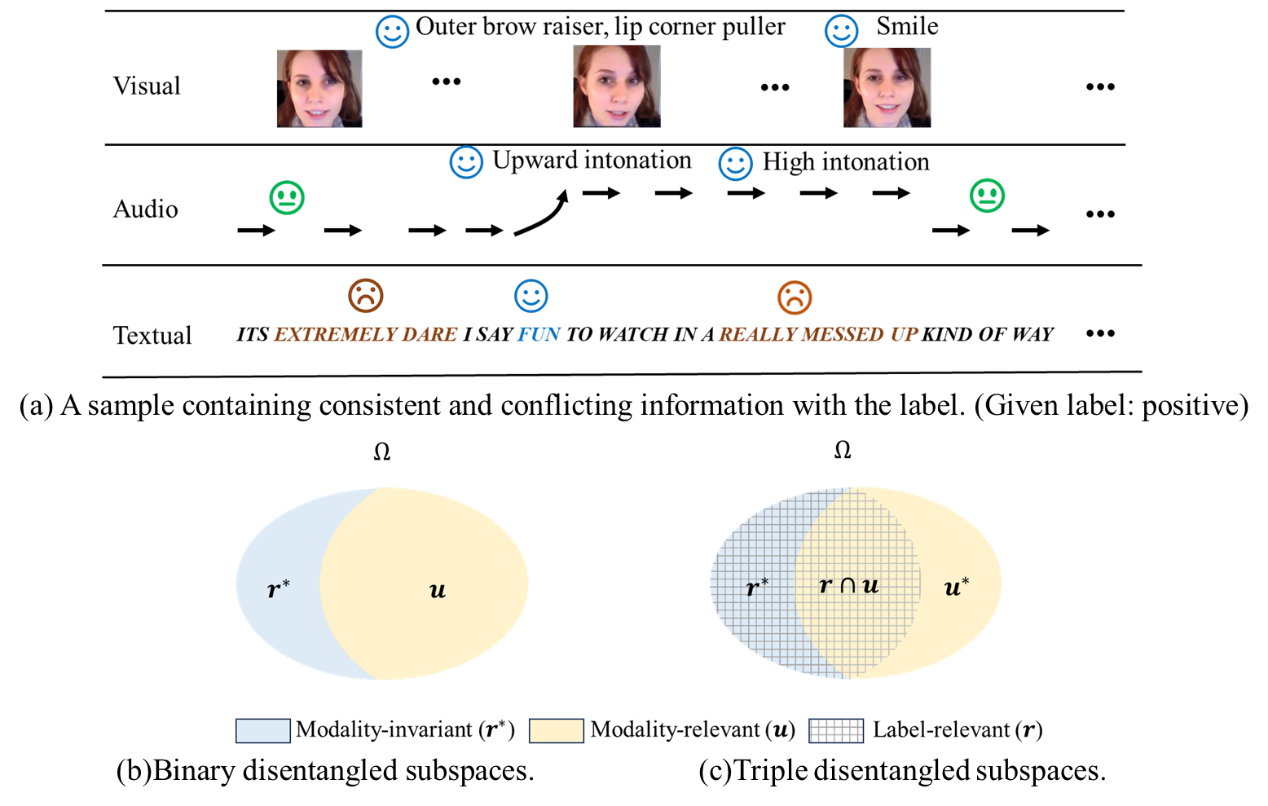
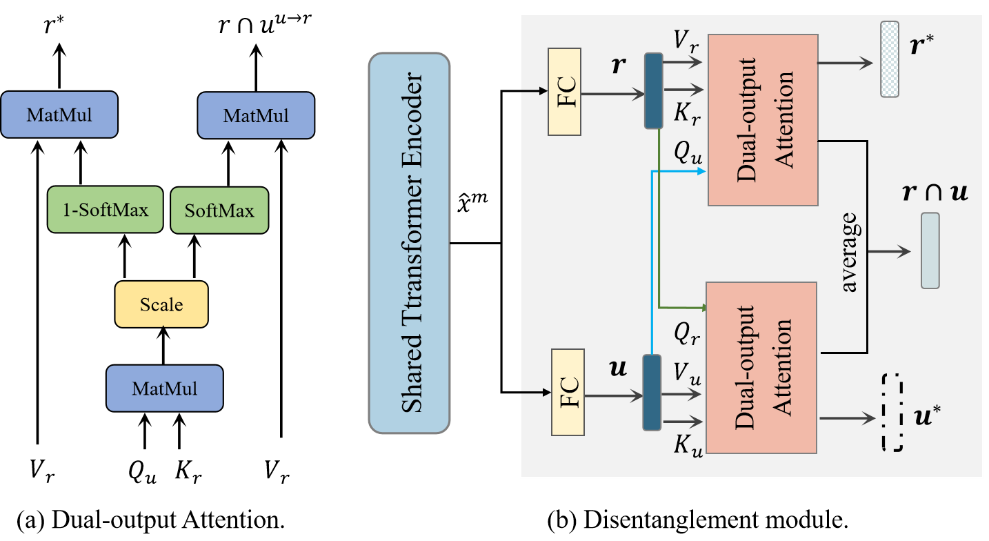
我们重新审视了解耦问题,并提出一种新的三解耦方法TriDiRA,从输入数据中解耦模态不变表征(r*),有效的模态特有表征(
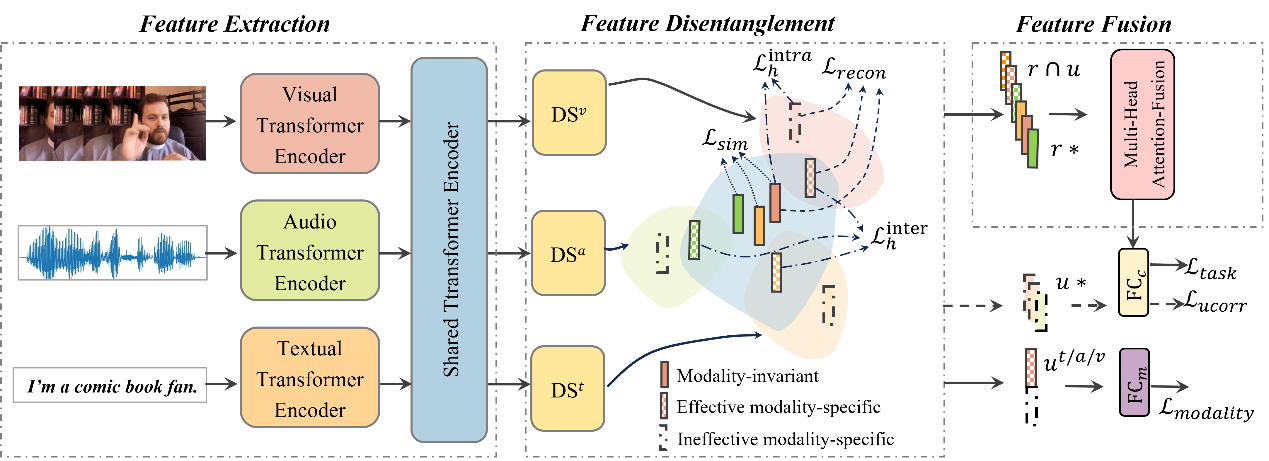
下图为解耦模块示意图:
3. “Leveraging Knowledge of Modality Experts for Incomplete Multimodal Learning”, Proc. ACM International Conference on Multimedia (ACMMM 2024) (Oral presentation, Acceptance rate: 3.97%).
多模态情感识别(MER)在实际应用中可能遇到因传感器损坏或隐私保护导致的模态数据缺失的场景。现有的不完备多模态学习方法主要通过学习更好的跨模态联合表征以提升模型在模态缺失场景中的鲁棒性,然而,我们的研究发现,这些方法往往忽略了学习模态特定的单模态表征,导致其在严重模态缺失(只有一个模态可用)的场景下表现不佳。为此,我们首次定义了模态缺失场景下的单模态表征和联合表征,并提出了一种新的框架,混合模态知识专家模型(MoMKE)去学习这些表征,其采用两阶段训练方式:1)单模态专家训练,每个模态专家学习对应的模态知识;2)专家混合训练,通过整合所有模态专家的知识,学习单模态和联合表征。我们还设计了一个特殊的软路由,通过动态混合单模态和联合表征,进一步丰富了学得的模态表征。在三个基准数据集上的不完备多模态实验中,MoMKE超过了先前的方法,在模态严重缺失的场景中提升尤其明显。论文中提供了可视化分析进一步揭示了单模态和联合表征各自在不完备多模态学习中的价值。
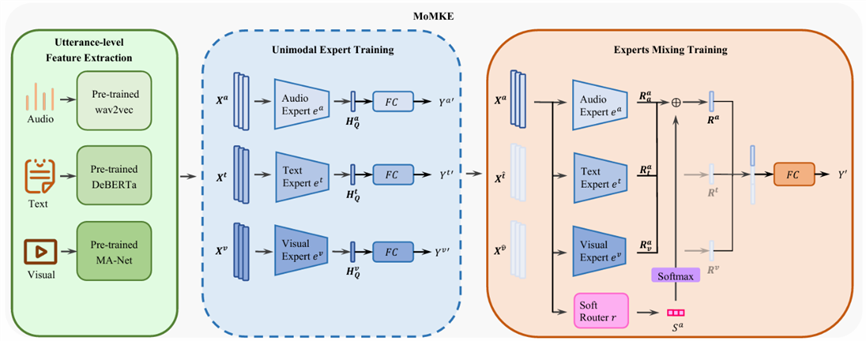
4. "Learning Subjective Time-Series Data via Utopia Label Distribution Approximation" Pattern Recognition, 2025. IF (7.5).
主观时间序列回归(Subjective Time-series Regression, STR)任务被广泛应用于多媒体社交网络中的情感分析、视频摘要、音乐情感识别等场景,其通常要求对视频或音频的每帧进行基于多位标注者主观认知的数值标注,用于反映情感极性、强度或帧的重要性评分。大多数现有STR方法忽视了STR数据中的标签分布偏差,导致模型学习产生偏差。要解决这个问题面临两大挑战:1)区别于一般的假设标签分布是均匀且已知的不平衡回归任务,STR任务的测试集标签分布通常是非均匀且未知的。2)时间序列数据在特征和标签空间的连续性同样导致了传统的不平衡采样方法的不适用。
在本文中,我们提出了乌托邦标签分布近似(ULDA)方法,通过对训练集标签分布进行高斯卷积,使其更接近现实世界中未知的(理想的)标签分布,从而间接逼近从真实世界采样的测试集的分布。为了在不破坏时序数据连续性的前提下构建乌托邦标签分布,我们引入了两个新方法:1)时间片段正态采样(TNS),在标签相近的连续时间片段内建模正态分布并通过蒙特卡洛采样生成新样本2)卷积加权损失(CWL),对冗余样本降低学习权重。
5. "Adaptive Mask Co-optimization for Modal Dependence in Multimodal Learning", Proc. Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2023) (Oral presentation, Acceptance rate: 5%),
在多模态学习中,模型常常受到某个或某些模态主导,如图中的模型严重依赖文字信息。这是因为不同模态提供的信息量不同,导致学习时各个模态对模型的贡献度不同。因此模型整体上更倾向于学习包含信息多,学习速度快,对模型贡献大的简单模态,而忽略其他较难学习的模态,导致模型不能充分学习困难模态的信息。当遇到简单模态和困难模态发生对调的样本时,困难模态无法发挥出应有的贡献,降低了识别的效果。
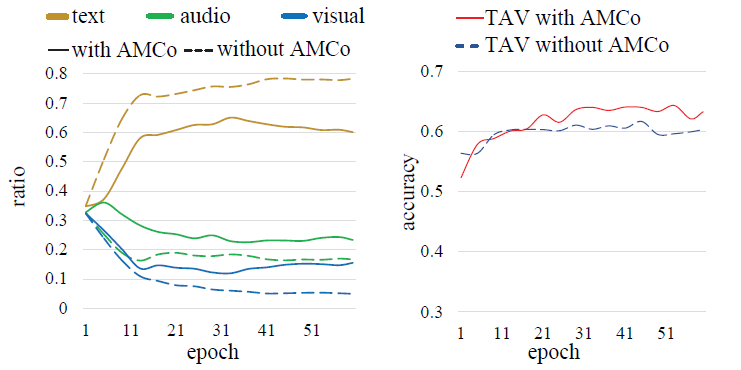
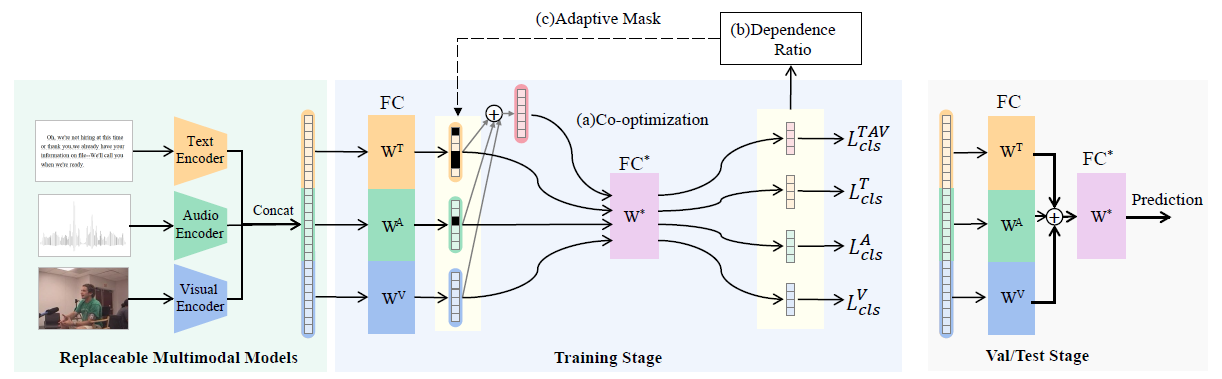
我们提出了一种新的插件模块,自适应掩码协同优化(AMCo),它可以插入到现有多模态学习模型中。主要包括三个部分:(a)联合优化:多个单模态分支和一个多模态分支协同优化,其不仅保留了模型在简单模态上的学习性能,也保证了困难模态的优化效果;(b)依赖比例:在FC*层之后计算每个模态的依赖;(c)自适应掩码:通过屏蔽依赖模态的特征,在学习中增大依赖模态学习的困难程度,以鼓励模型从困难模态中学习更多的信息。
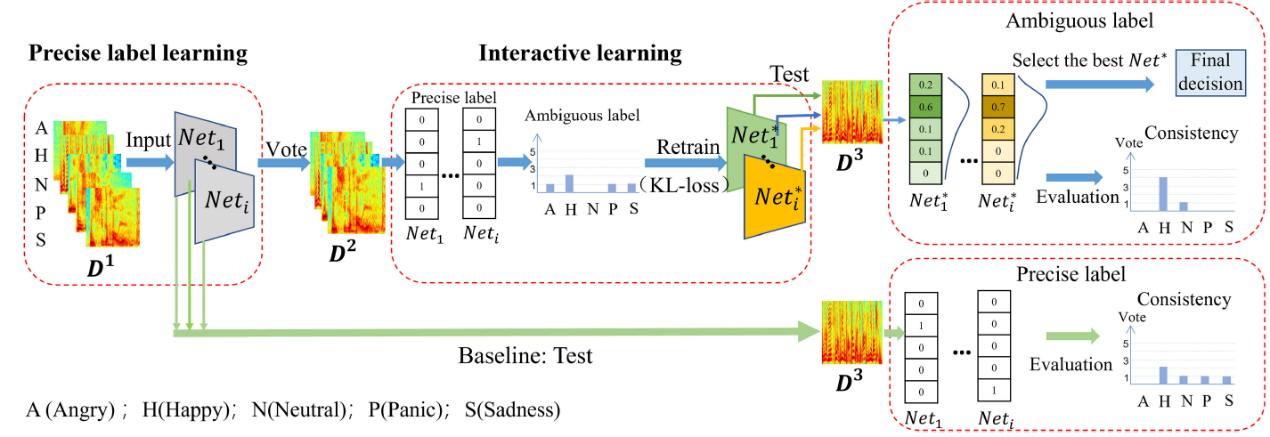
6. "Multi-Classifier Interactive Learning for Ambiguous Speech Emotion Recognition", IEEE/ACM Transactions on Audio, Speech and Language Processing, 2022.
本研究面向模糊情感分类问题,首先,本文中使用模糊标签代替传统的精确标签进行学习。模糊标签以分布的形式表示该样本属于各类的概率,能更准确地表示模糊数据的特点。在实际的学术研究中,为了构建模糊标签,需要多位经过训练的专家对样本进行标注,极其耗费人力物力,成本很高。所以本论文中利用多个这样的分类器对无标签模糊样本进行分类投票处理。通过分类器自动构建模糊标签,能够节省成本,更加准确地表现出模糊样本的性质。
另外,从最优交互理论得到启发,在面对较为困难的问题时,如果允许集体对各自获取的信息以及判断依据等进行交流学习,再进行判断,能够取得更好的决策结果。同时,交互学习也能提高个体的判断力。由此得到启发,本论文中利用多个结构不同的分类网络作为分类器,使用经过训练的分类器来代替决策者,通过分类器间投票构建模糊标签,将模糊标签作为分类器间信息沟通的媒介,将模糊标签代替精确标签重新对分类器进行训练,从而达到交互学习的目的,提高各个分类器各自的性能以及分类器间的一致性。
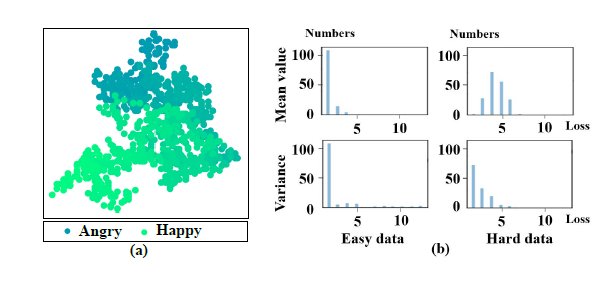
7. "Progressive Co-teaching for Ambiguous Speech Emotion Recognition", Proc. Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2021), 2021.
情感识别任务中存在大量模糊数据,如图所示,这部分数据位于分类边界上,很难区分。在现有方法中常依赖于专家投票构建的软标签进行建模。本研究主要研究目标为提出一种模拟人类学习困难问题的方法,提升模型对于情感模糊数据,即困难数据的学习能力。
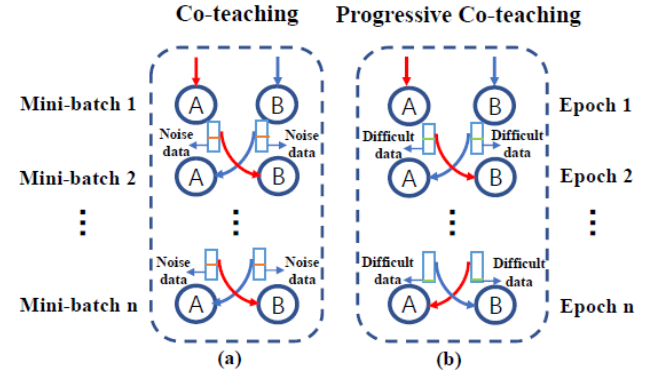
本论文中提出了一种基于协同教学的渐进式协同教学(Progressive Co-teaching, PCT)方法。不同于协同教学,PCT方法采用由易到难的学习策略来处理有歧义的语音情感数据。通过同时训练两个网络,并为彼此挑选简单数据,使网络的分类能力在训练过程中逐渐增强,并逐步学习到模糊数据。
- 模式挖掘
模式是用来说明事物结构的主观理性形式概念,是事物一般性和特殊性的衔接。人们进行决策时需要模式,但常常不能直接获得。例如,在科学研究的双盲实验中需要设计实验组和对照组,受试者接受大量不同刺激,做出相应的反应(反应是刺激的标签,要做分类)。在这些表象之下,研究人员希望找到造成不同反应的刺激之间有哪些特点(自动寻找特点要做聚类),从而更好地进行相关性和因果关系的分析。模式也存在于各种常见的工业场景中。如在视频分析中,需要了解高分、低分影片的差异(分类),挖掘各自的特点(聚类),从而更好的指导投资人与导演等从事影视工作。在工业设计中,设计师期望了解外观受欢迎和不受欢迎产品的差别,更希望知道优秀产品的设计元素。当然,此类问题可以从双类别扩展到多类别。
一个模式必须具备两种性质:判别性和频繁性。判别性代表表明该模式属于某一特定类别,不同时出现在多个类别中,能够衡量该模式是否具有有效信息(例如树木、天空出现在很多类别中,但是这些模式不具备研究价值);频繁性代表该模式是否频繁出现,决定了模式是否具有代表性(例如只在某一类别中出现少数几次的模式也不具有研究意义)。
以下是团队已有的一些成果:
- "Multi-pattern Mining using Pattern-level Contrastive Learning and Multi-pattern Activation Map", IEEE Trans. on Neural Networks and Learning Systems, IF (14.255).
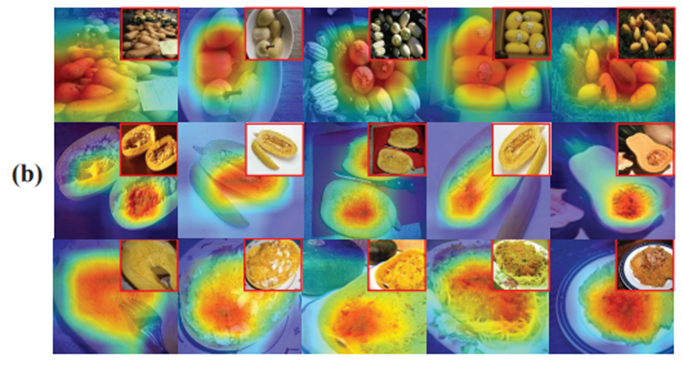
本论文提出了一种新颖的视觉任务“多模式挖掘”,该任务旨在挖掘复杂类别中的多个不同视觉模式,它的挑战在于要同时完成有监督的分类任务和无监督的聚类任务。多模式挖掘在机器学习领域中鲜有探索,但在社会心理学、文化心理学、创新设计、生物制药领域的复杂问题解决中有着广泛的价值。
下图展示了本方法在ILSVRC2012中的‘档案室’‘南瓜意面’两类数据中的结果。红色到深蓝色代表网络从感兴趣到不感兴趣,每张热力图的右上角是原图。可以看出,在‘档案室’中,每种模式分别是,整齐排列的档案、人像后的档案、存储档案的柜子三种模式。在‘南瓜意面’中,三种模式分别是,完整的南瓜、南瓜壤、做好的意面三种模式。

- "A Joint Framework for Mining Discriminative and Frequent Visual Representation", Neurocomputing (ELSEVIER), 2022, IF (5.719).
本论文提出了一种联合挖掘具有判别性和频繁性的视觉模式表征的方法,利用分类任务中的交叉熵损失保证模式的判别性,同时设计了一种相似关注损失来保证模式的频繁性,两者联合优化,避免模式判别性和频繁性单独优化导致次优解。
下图展示了本方法在 iNaturalist-100 数据集中发现的视觉表征的实例。最上方的是原图,中间的是热力图,红色到深蓝色代表网络从感兴趣到不感兴趣,最下方的是感兴趣区域的裁剪图像。


- "Jointly Discriminating and Frequent Visual Representation Mining", Proc. Asian Conf. on Computer Vision (ACCV 2020), 2020.
本论文提出了联合挖掘具有判别性和频繁性的视觉模式表征的方法,利用分类任务中的交叉熵损失保证模式的判别性,同时使用三元损失来保证模式的频繁性,两者联合优化,避免模式判别性和频繁性单独优化导致的次优解。
·唇语识别
唇语识别的目标是通过分析说话人的嘴唇移动方式来理解他们所说的内容。它在人类交流和语言理解中起到关键作用,因此有巨大的应用潜力,如安防设备、噪声环境中的语言识别和生物认证、改进助听器、公共场所的无声听写。
唇语识别研究由易到难被分为已见人(seen speaker)和未见人(unseen speaker)唇语识别,其区别在于测试集中是否包含在训练集中出现过的说话人。
以下是团队已取得的成果:
- "CALLip: Lipreading using Contrastive and Attribute Learning", Proc. the 29th ACM International Conference on Multimedia (ACMMM 2021), 2021.

本论文关注唇语识别中两个严峻挑战:1)不同人在说相同的话语时,唇部动作和嘴唇外形的差异相当大;2)同一个人在说出容易混淆的音素时,唇部动作相似。
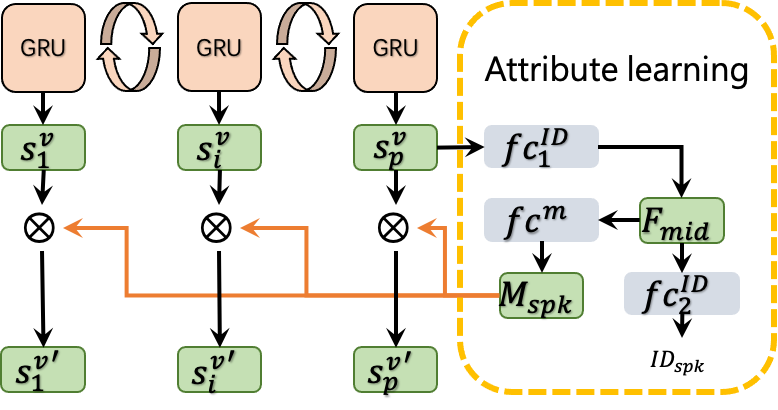
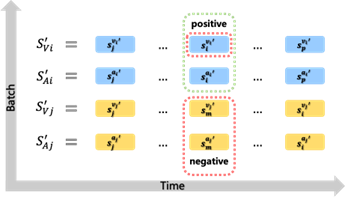
为了解决这两个问题,我们采用属性学习模块将说话人表征转换为相应的掩码用于减少不同说话人唇形差异带来的干扰。对比学习模块使用具有更高区分度的音频信号提升低分辨率视觉特征的可分性。
- 运动感知
在计算机视觉领域,运动感知主要包括运动目标检测、跟踪、姿态估计、碰撞预测等方面。其中,碰撞预测可以应用在广泛的现实场景中,如自动驾驶等。具体到车辆碰撞预测问题而言,其具有:包含自我车辆运动、发生突然、长尾分布场景以及多样的发生方式等特点。复杂的环境给碰撞预测带来了巨大的挑战。
以下是团队已取得的成果:
- "A Single-Pathway Biomimetic Model for Potential Collision Prediction", Proc. Chinese Conf. on Pattern Recognition and Computer Vision (PRCV 2022).
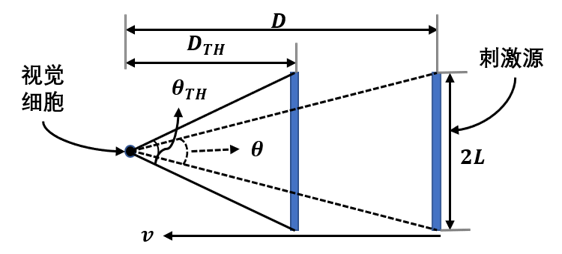
此研究针对路上车辆碰撞预测问题提出了一种基于生物视觉系统LGMD的改进LGMD2方法SLGMD2。现有的方法普遍不区分第一和第三人称视角,其本质是视频异常检测,只关注于是否发生碰撞而不关注碰撞发生时刻的深度学习方法。LGMD是一种可靠的生物学模型,其机理主要与目标与眼睛的夹角以及角速度大小有关。
下图给出了LGMD生物机理的数学模型示意图。
下图给出了关于碰撞预测的问题定义示意图。

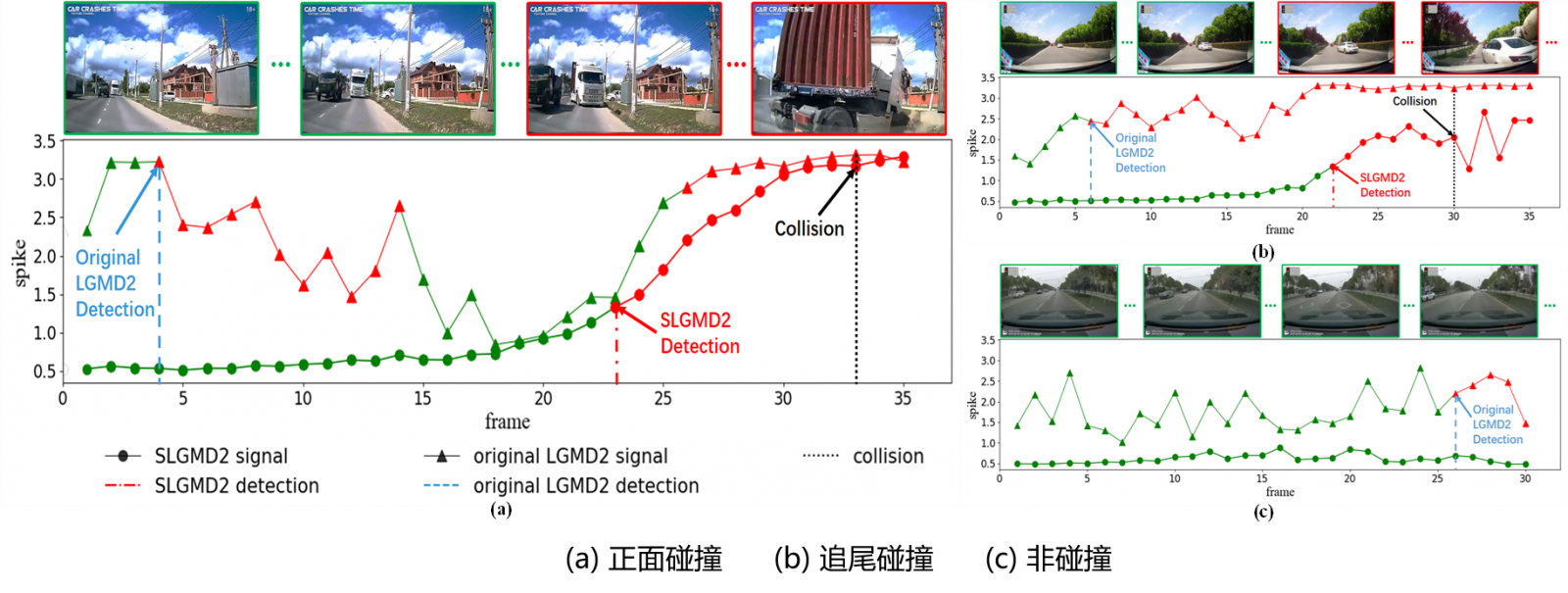
下图给出了SLGMD2与原始LGMD2方法在不同碰撞场景下的预测结果对比图。
2. “A General Inlier Estimation for Moving Camera Motion Segmentation”, IPSJ Transactions on Computer Vision and Applications, 2015. (Invited paper)
3. “Inlier Estimation for Moving Camera Motion Segmentation”, Proc. 12th Asian Conf. on Computer Vision (ACCV 2014), (Oral presentation, Acceptance rate: 3.8%), 2014.
本文介绍了一种用于移动相机运动分割的通用估计方法。在移动相机视频中,可以理解任意运动是旋转、平移和扩散三种基本运动的不同线性组合。不同于以往的工作,我们提出了一种统一的运动分解模型分析运动的一致性,使得异常运动检测变得容易。此外,移动相机还会引入三维运动,深度不连续性会导致运动不连续性,从而严重破坏了运动的一致性。该方法的优点是不需要假设任何先验知识。
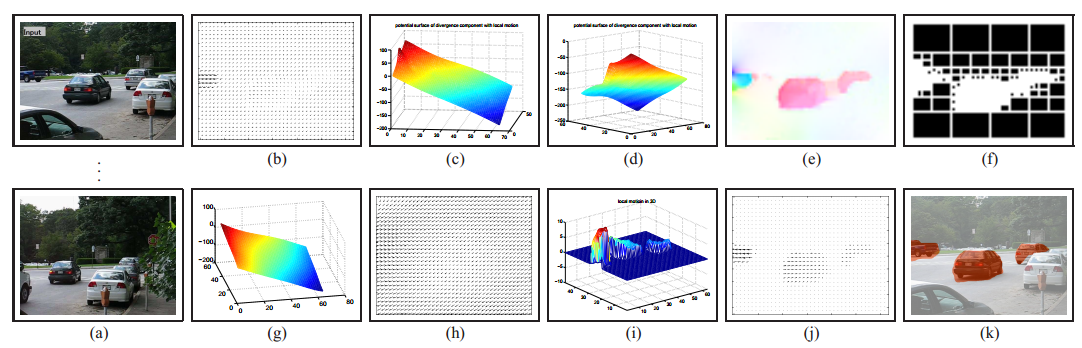
下图展示了平移场景中三辆车的示例结果。(a)为连续的20帧图像,(b)两个相邻帧的光流,(c)和(d)为在光流上应用修正后的HDD后的旋度和发散分量,(e)为IM图,(f)为异常运动可视化,(g)使用低阶多项式估计的一致运动场,(h)估计的相机运动场,(i)和(j)展示了恢复了的运动物体的运动流,(k)分割结果。
下图展示了使用光流的其他六种方法和我们的方法在具有挑战性的场景中的分割结果:(a)输入视频,从上到下:cars2、people2、forest、store、parachute、traffic,(b)GME-SEG,(c)LS,(d)GD,(e)Filter,(f)RANSAC,(g)FOF,(h)FOF+color+prior,(i)我们的结果,(j)label。

4.“Mixed-Motion Segmentation using Helmholtz Decomposition”, Proc. 16th Meeting on Image Recognition and Understanding (MIRU 2013), Outstanding Paper Award, 2013.